What is a regular expression which will match a valid domain name without a subdomain?
RegexValidationDomain NameRegex Problem Overview
I need to validate a domain name:
google.com
stackoverflow.com
So a domain in its rawest form - not even a subdomain like www.
- Characters should only be a-z | A-Z | 0-9 and period(.) and dash(-)
- The domain name part should not start or end with dash (-) (e.g. -google-.com)
- The domain name part should be between 1 and 63 characters long
The extension (TLD) can be anything under #1 rules for now, I may validate them against a list later, it should be 1 or more characters though
Edit: TLD is apparently 2-6 chars as it stands
no. 4 revised: TLD should actually be labelled "subdomain" as it should include things like .co.uk -- I would imagine the only validation possible (apart from checking against a list) would be 'after the first dot there should be one or more characters under rules #1
Thanks very much, believe me I did try!
Regex Solutions
Solution 1 - Regex
I know that this is a bit of an old post, but all of the regular expressions here are missing one very important component: the support for IDN domain names.
IDN domain names start with xn--. They enable extended UTF-8 characters in domain names. For example, did you know "♡.com" is a valid domain name? Yeah, "love heart dot com"! To validate the domain name, you need to let http://xn--c6h.com/ pass the validation.
Note, to use this regex, you will need to convert the domain to lower case, and also use an IDN library to ensure you encode domain names to ACE (also known as "ASCII Compatible Encoding"). One good library is GNU-Libidn.
idn(1) is the command line interface to the internationalized domain name library. The following example converts the host name in UTF-8 into ACE encoding. The resulting URL https://nic.xn--flw351e/ can then be used as ACE-encoded equivalent of https://nic.谷歌/.
$ idn --quiet -a nic.谷歌
nic.xn--flw351e
This magic regular expression should cover most domains (although, I am sure there are many valid edge cases that I have missed):
^((?!-))(xn--)?[a-z0-9][a-z0-9-_]{0,61}[a-z0-9]{0,1}\.(xn--)?([a-z0-9\-]{1,61}|[a-z0-9-]{1,30}\.[a-z]{2,})$
When choosing a domain validation regex, you should see if the domain matches the following:
- xn--stackoverflow.com
- stackoverflow.xn--com
- stackoverflow.co.uk
If these three domains do not pass, your regular expression may be not allowing legitimate domains!
Check out The Internationalized Domain Names Support page from Oracle's International Language Environment Guide for more information.
Feel free to try out the regex here: http://www.regexr.com/3abjr
ICANN keeps a list of tlds that have been delegated which can be used to see some examples of IDN domains.
Edit:
^(((?!\-))(xn\-\-)?[a-z0-9\-_]{0,61}[a-z0-9]{1,1}\.)*(xn\-\-)?([a-z0-9\-]{1,61}|[a-z0-9\-]{1,30})\.[a-z]{2,}$
This regular expression will stop domains that have '-' at the end of a hostname as being marked as being valid. Additionally, it allows unlimited subdomains.
Solution 2 - Regex
Well, it's pretty straightforward a little sneakier than it looks (see comments), given your specific requirements:
/^[a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]\.[a-zA-Z]{2,}$/
But note this will reject a lot of valid domains.
Solution 3 - Regex
My RegEx is next:
^[a-zA-Z0-9][a-zA-Z0-9-_]{0,61}[a-zA-Z0-9]{0,1}\.([a-zA-Z]{1,6}|[a-zA-Z0-9-]{1,30}\.[a-zA-Z]{2,3})$
it's ok for i.oh1.me and for wow.british-library.uk
UPD
Here is updated rule
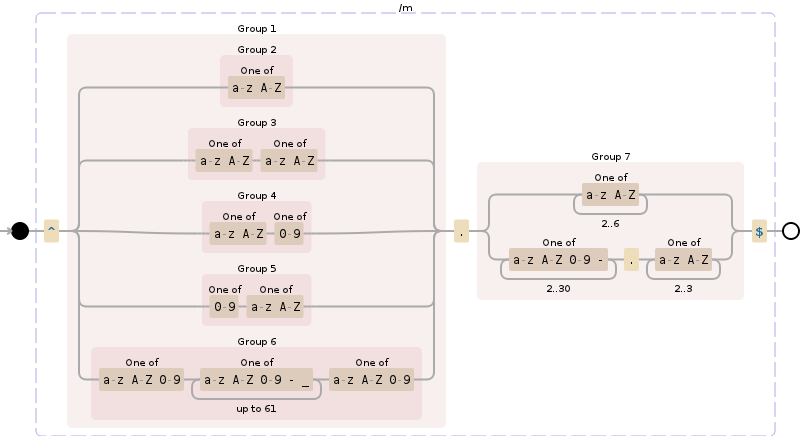
^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|([a-zA-Z]{1}[0-9]{1})|([0-9]{1}[a-zA-Z]{1})|([a-zA-Z0-9][a-zA-Z0-9-_]{1,61}[a-zA-Z0-9]))\.([a-zA-Z]{2,6}|[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3})$
https://www.debuggex.com/r/y4Xe_hDVO11bv1DV
now it check for - or _ in the start or end of domain label.
Solution 4 - Regex
My bet:
^(?:[a-z0-9](?:[a-z0-9-]{0,61}[a-z0-9])?\.)+[a-z0-9][a-z0-9-]{0,61}[a-z0-9]$
Explained:
Domain name is built from segments. Here is one segment (except final):
[a-z0-9](?:[a-z0-9-]{0,61}[a-z0-9])?
It can have 1-63 characters, does not start or end with '-'.
Now append '.' to it and repeat at least one time:
(?:[a-z0-9](?:[a-z0-9-]{0,61}[a-z0-9])?\.)+
Then attach final segment, which is 2-63 characters long:
[a-z0-9][a-z0-9-]{0,61}[a-z0-9]
Test it here: http://regexr.com/3au3g
Solution 5 - Regex
This answer is for domain names (including service RRs), not host names (like an email hostname).
^(?=.{1,253}\.?$)(?:(?!-|[^.]+_)[A-Za-z0-9-_]{1,63}(?<!-)(?:\.|$)){2,}$
It is basically mkyong's answer and additionally:
- Max length of 255 octets including length prefixes and null root.
- Allow trailing '.' for explicit dns root.
- Allow leading '_' for service domain RRs, (bugs: doesn't enforce 15 char max for _ labels, nor does it require at least one domain above service RRs)
- Matches all possible TLDs.
- Doesn't capture subdomain labels.
By Parts
Lookahead, limit max length between ^$ to 253 characters with optional trailing literal '.'
(?=.{1,253}\.?$)
Lookahead, next character is not a '-' and no '_' follows any characters before the next '.'. That is to say, enforce that the first character of a label isn't a '-' and only the first character may be a '_'.
(?!-|[^.]+_)
Between 1 and 63 of the allowed characters per label.
[A-Za-z0-9-_]{1,63}
Lookbehind, previous character not '-'. That is to say, enforce that the last character of a label isn't a '-'.
(?<!-)
Force a '.' at the end of every label except the last, where it is optional.
(?:\.|$)
Mostly combined from above, this requires at least two domain levels, which is not quite correct, but usually a reasonable assumption. Change from {2,} to + if you want to allow TLDs or unqualified relative subdomains through (eg, localhost, myrouter, to.)
(?:(?!-|[^.]+_)[A-Za-z0-9-_]{1,63}(?<!-)(?:\.|$)){2,}
Unit tests for this expression.
Solution 6 - Regex
Just a minor correction - the last part should be up to 6. Hence,
^[a-z0-9]+([\-\.]{1}[a-z0-9]+)*\.[a-z]{2,6}$
The longest TLD is museum (6 chars) - http://en.wikipedia.org/wiki/List_of_Internet_top-level_domains
Solution 7 - Regex
Accepted answer not working for me, try this :
> ^((?!-)[A-Za-z0-9-]{1,63}(?<!-)\.)+[A-Za-z]{2,6}$
Visit this Unit Test Cases for validation.
Solution 8 - Regex
^[a-z0-9]+([\-\.]{1}[a-z0-9]+)*\.[a-z]{2,7}$
[domain - lower case letters and 0-9 only] [can have a hyphen] + [TLD - lower case only, must be beween 2 and 7 letters long]
http://rubular.com/ is brilliant for testing regular expressions!
Edit: Updated TLD maximum to 7 characters for '.rentals' as Dan Caddigan pointed out.
Solution 9 - Regex
Thank you for pointing right direction in domain name validation solutions in other answers. Domain names could be validated in various ways.
If you need to validate IDN domain in it's human readable form, regex \p{L} will help. This allows to match any character in any language.
Note that last part might contain hyphens too! As punycode encoded Chineese names might have unicode characters in tld.
I've came to solution which will match for example:
- google.com
- masełkowski.pl
- maselkowski.pl
- m.maselkowski.pl
- www.masełkowski.pl.com
- xn--masekowski-d0b.pl
- 中国互联网络信息中心.中国
- xn--fiqa61au8b7zsevnm8ak20mc4a87e.xn--fiqs8s
Regex is:
^[0-9\p{L}][0-9\p{L}-\.]{1,61}[0-9\p{L}]\.[0-9\p{L}][\p{L}-]*[0-9\p{L}]+$
NOTE: This regexp is quite permissive, as is current domain names allowed character set.
UPDATE: Even more simplified, as a-aA-Z\p{L} is same as just \p{L}
NOTE2: The only problem is that it will match domains with double dots in it... , like masełk..owski.pl. If anyone know how to fix this please improve.
Solution 10 - Regex
Not enough rep yet to comment. In response to paka's solution, I found I needed to adjust three items:
- The dash and underscore were moved due to the dash being interpreted as a range (as in "0-9")
- Added a full stop for domain names with many subdomains
- Extended the potential length for the TLDs to 13
Before:
^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|([a-zA-Z]{1}[0-9]{1})|([0-9]{1}[a-zA-Z]{1})|([a-zA-Z0-9][a-zA-Z0-9-_]{1,61}[a-zA-Z0-9]))\.([a-zA-Z]{2,6}|[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3})$
After:
^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|([a-zA-Z]{1}[0-9]{1})|([0-9]{1}[a-zA-Z]{1})|([a-zA-Z0-9][-_\.a-zA-Z0-9]{1,61}[a-zA-Z0-9]))\.([a-zA-Z]{2,13}|[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3})$
Solution 11 - Regex
As already pointed out it's not obvious to tell subdomains in the practical sense (e.g. .co.uk domains). We use this regex to validate domains which occur in the wild. It covers all practical use cases I know of. New ones are welcome. According to our guidelines it avoids non-capturing groups and greedy matching.
^(?!.*?_.*?)(?!(?:[\d\w]+?\.)?\-[\w\d\.\-]*?)(?![\w\d]+?\-\.(?:[\d\w\.\-]+?))(?=[\w\d])(?=[\w\d\.\-]*?\.+[\w\d\.\-]*?)(?![\w\d\.\-]{254})(?!(?:\.?[\w\d\-\.]*?[\w\d\-]{64,}\.)+?)[\w\d\.\-]+?(?<![\w\d\-\.]*?\.[\d]+?)(?<=[\w\d\-]{2,})(?<![\w\d\-]{25})$
Proof, explanation and examples: https://regex101.com/r/FLA9Bv/9 (Note: currently only works in Chrome because the regex uses lookbehinds which are only supported in ECMA2018)
There're two approaches to choose from when validating domains.
By-the-books FQDN matching (theoretical definition, rarely encountered in practice):
- max 253 character long (as per RFC-1035/3.1, RFC-2181/11)
- max 63 character long per label (as per RFC-1035/3.1, RFC-2181/11)
- any characters are allowed (as per RFC-2181/11)
- TLDs cannot be all-numeric (as per RFC-3696/2)
- FQDNs can be written in a complete form, which includes the root zone (the trailing dot)
Practical / conservative FQDN matching (practical definition, expected and supported in practice):
- by-the-books matching with the following exceptions/additions
- valid characters:
[a-zA-Z0-9.-] - labels cannot start or end with hyphens (as per RFC-952 and RFC-1123/2.1)
- TLD min length is 2 character, max length is 24 character as per currently existing records
- don't match trailing dot
Solution 12 - Regex
For new gTLDs
/^((?!-)[\p{L}\p{N}-]+(?<!-)\.)+[\p{L}\p{N}]{2,}$/iu
Solution 13 - Regex
^[a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]\.[a-zA-Z]+(\.[a-zA-Z]+)$
Solution 14 - Regex
^((localhost)|((?!-)[A-Za-z0-9-]{1,63}(?<!-)\.)+[A-Za-z]{2,253})$
Thank you @mkyong for the basis for my answer. I've modified it to support longer acceptable labels.
Also, "localhost" is technically a valid domain name. I will modify this answer to accommodate internationalized domain names.
Solution 15 - Regex
Here is complete code with example:
<?php
function is_domain($url)
{
$parse = parse_url($url);
if (isset($parse['host'])) {
$domain = $parse['host'];
} else {
$domain = $url;
}
return preg_match('/^(?!\-)(?:[a-zA-Z\d\-]{0,62}[a-zA-Z\d]\.){1,126}(?!\d+)[a-zA-Z\d]{1,63}$/', $domain);
}
echo is_domain('example.com'); //true
echo is_domain('https://example.com'); //true
echo is_domain('https://.example.com'); //false
echo is_domain('https://localhost'); //false
Solution 16 - Regex
> ^[a-zA-Z0-9][-a-zA-Z0-9]+[a-zA-Z0-9].[a-z]{2,3}(.[a-z]{2,3})?(.[a-z]{2,3})?$
Examples that work:
stack.com
sta-ck.com
sta---ck.com
9sta--ck.com
sta--ck9.com
stack99.com
99stack.com
sta99ck.com
It will also work for extensions
.com.uk
.co.in
.uk.edu.in
Examples that will not work:
-stack.com
it will work even with the longest domain extension ".versicherung"
Solution 17 - Regex
/^((([a-zA-Z]{1,2})|([0-9]{1,2})|([a-zA-Z0-9]{1,2})|([a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]))\.)+[a-zA-Z]{2,6}$/
-
([a-zA-Z]{1,2})-> for accepting only two characters. -
([0-9]{1,2})-> for accepting two numbers only
if anything exceeds beyond two ([a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]) this regex will take care of that.
If we want to do the matching for at least one time + will be used.
Solution 18 - Regex
^((?!-))(xn--)?[a-z0-9][a-z0-9-_]{0,61}[a-z0-9]{0,}\.?((xn--)?([a-z0-9\-.]{1,61}|[a-z0-9-]{0,30})\.[a-z-1-9]{2,})$
will validate such domains as яндекс.рф after encoding.
https://regex101.com/r/Hf8wFM/1 - sandbox
Solution 19 - Regex
The following regex extracts the sub, root and tld of a given domain:
^(?<domain>(?<domain_sub>(?:[^\/\"\]:\.\s\|\-][^\/\"\]:\.\s\|]*?\.)*?)(?<domain_root>[^\/\"\]:\s\.\|\n]+\.(?<domain_tld>(?:xn--)?[\w-]{2,7}(?:\.[a-zA-Z-]{2,3})*)))$
Tested for the following domains:
* stack.com
* sta-ck.com
* sta---ck.com
* 9sta--ck.com
* sta--ck9.com
* stack99.com
* 99stack.com
* sta99ck.com
* google.com.uk
* google.co.in
* google.com
* masełkowski.pl
* maselkowski.pl
* m.maselkowski.pl
* www.masełkowski.pl.com
* xn--masekowski-d0b.pl
* xn--fiqa61au8b7zsevnm8ak20mc4a87e.xn--fiqs8s
* xn--stackoverflow.com
* stackoverflow.xn--com
* stackoverflow.co.uk
Solution 20 - Regex
I did the below to simple fetch the domain along with the protocol. Example: https://www.facebook.com/profile/user/ ftp://182.282.34.337/movies/M
use the below Regex pattern : [a-zA-Z0-9]+://.*?/
will get you the output : https://www.facebook.com/ ftp://192.282.34.337/
Solution 21 - Regex
Quite simple, quite permissive. It will have false positives like -notvalid.at-all, but it won't have false negatives.
/^([0-9a-z-]+\.?)+$/i
It makes sure it has a sequence of letters numbers and dashes that could end with a dot, and following it, any number of those kind of sequences.
The things I like about this regexp: it's short (maybe the shortest here), easily understandable, and good enough for validating user input errors in the client side.
Solution 22 - Regex
For Javascript you can have a look into the validator library: https://www.npmjs.com/package/validator
Method: isFQDN(str [, options])
Solution 23 - Regex
There are several reasons why one may need to validate a domain or an Internationalized Domain Name.
To accept only the functional domains which resolve when probed through a DNS query To accept the strings which can potentially act (get registered and subsequently resolved, or only for the sake of information) as domain name Depending on the nature of the need, the ways in which the domain name can be validated, differs a great deal.
For validating the domain names, only from pure technical specification point of view, regardless of it's resolvability vis-a-vis the DNS, is a slightly more complex problem than merely writing a Regex with certain number of Unicode classes.
There is a host of RFCs (5891,5892,5893,5894 and 5895) that together define, the structure of a valid domain ( IDN in specific, domain in general) name. It involves not only various Unicode Character classes, but also includes some context specific rules which need a full-fledged algorithm of their own. Typically, all the leading programming languages and frameworks provide a way to validate the domain names as per the latest IDNA Protocol i.e. IDNA 2008.
Since your question is programming language neutral, I would suggest possible options for most of the major programming languages.
For validating the domain names, do refer to the very thoroughly research document produced by the "Universal Acceptance Steering Group" (https://uasg.tech/), titled,
- "UASG 018A UA Compliance of Some Programming Language Libraries and Frameworks (https://uasg.tech/download/uasg-018a-ua-compliance-of-some-programming-language-libraries-and-frameworks-en/ as well as
- "UASG 037 UA-Readiness of Some Programming Language Libraries and Frameworks EN" (https://uasg.tech/download/uasg-037-ua-readiness-of-some-programming-language-libraries-and-frameworks-en/).
Both the documents list various programming language libraries that can be used to validate the domain names.
Solution 24 - Regex
Check whether each part of the domain is not longer than 63 characters, and allow internationalized domain names using the punycode notation:
\b((?=[a-z0-9-]{1,63}\.)(xn--)?[a-z0-9]+(-[a-z0-9]+)*\.)+[a-z]{2,63}\b