SQLite - UPSERT *not* INSERT or REPLACE
SqlSqliteUpsertSql Problem Overview
http://en.wikipedia.org/wiki/Upsert
https://stackoverflow.com/questions/13540/insert-update-stored-proc-on-sql-server
Is there some clever way to do this in SQLite that I have not thought of?
Basically I want to update three out of four columns if the record exists, If it does not exists I want to INSERT the record with the default (NUL) value for the fourth column.
The ID is a primary key so there will only ever be one record to UPSERT.
(I am trying to avoid the overhead of SELECT in order to determine if I need to UPDATE or INSERT obviously)
Suggestions?
I cannot confirm that Syntax on the SQLite site for TABLE CREATE. I have not built a demo to test it, but it doesn't seem to be supported.
If it was, I have three columns so it would actually look like:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
Blob1 BLOB ON CONFLICT REPLACE,
Blob2 BLOB ON CONFLICT REPLACE,
Blob3 BLOB
);
but the first two blobs will not cause a conflict, only the ID would So I assume Blob1 and Blob2 would not be replaced (as desired)
UPDATEs in SQLite when binding data are a complete transaction, meaning Each sent row to be updated requires: Prepare/Bind/Step/Finalize statements unlike the INSERT which allows the use of the reset function
The life of a statement object goes something like this:
- Create the object using sqlite3_prepare_v2()
- Bind values to host parameters using sqlite3_bind_ interfaces.
- Run the SQL by calling sqlite3_step()
- Reset the statement using sqlite3_reset() then go back to step 2 and repeat.
- Destroy the statement object using sqlite3_finalize().
UPDATE I am guessing is slow compared to INSERT, but how does it compare to SELECT using the Primary key?
Perhaps I should use the select to read the 4th column (Blob3) and then use REPLACE to write a new record blending the original 4th Column with the new data for the first 3 columns?
Sql Solutions
Solution 1 - Sql
Assuming three columns in the table: ID, NAME, ROLE
BAD: This will insert or replace all columns with new values for ID=1:
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES (1, 'John Foo', 'CEO');
BAD: This will insert or replace 2 of the columns... the NAME column will be set to NULL or the default value:
INSERT OR REPLACE INTO Employee (id, role)
VALUES (1, 'code monkey');
GOOD: Use SQLite On conflict clause UPSERT support in SQLite! UPSERT syntax was added to SQLite with version 3.24.0!
UPSERT is a special syntax addition to INSERT that causes the INSERT to behave as an UPDATE or a no-op if the INSERT would violate a uniqueness constraint. UPSERT is not standard SQL. UPSERT in SQLite follows the syntax established by PostgreSQL.

GOOD but tedious: This will update 2 of the columns. When ID=1 exists, the NAME will be unaffected. When ID=1 does not exist, the name will be the default (NULL).
INSERT OR REPLACE INTO Employee (id, role, name)
VALUES ( 1,
'code monkey',
(SELECT name FROM Employee WHERE id = 1)
);
This will update 2 of the columns. When ID=1 exists, the ROLE will be unaffected. When ID=1 does not exist, the role will be set to 'Benchwarmer' instead of the default value.
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES ( 1,
'Susan Bar',
COALESCE((SELECT role FROM Employee WHERE id = 1), 'Benchwarmer')
);
Solution 2 - Sql
INSERT OR REPLACE is NOT equivalent to "UPSERT".
Say I have the table Employee with the fields id, name, and role:
INSERT OR REPLACE INTO Employee ("id", "name", "role") VALUES (1, "John Foo", "CEO")
INSERT OR REPLACE INTO Employee ("id", "role") VALUES (1, "code monkey")
Boom, you've lost the name of the employee number 1. SQLite has replaced it with a default value.
The expected output of an UPSERT would be to change the role and to keep the name.
Solution 3 - Sql
Eric B’s answer is OK if you want to preserve just one or maybe two columns from the existing row. If you want to preserve a lot of columns, it gets too cumbersome fast.
Here’s an approach that will scale well to any amount of columns on either side. To illustrate it I will assume the following schema:
CREATE TABLE page (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE,
title TEXT,
content TEXT,
author INTEGER NOT NULL REFERENCES user (id),
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Note in particular that name is the natural key of the row – id is used only for foreign keys, so the point is for SQLite to pick the ID value itself when inserting a new row. But when updating an existing row based on its name, I want it to continue to have the old ID value (obviously!).
I achieve a true UPSERT with the following construct:
WITH new (name, title, author) AS ( VALUES('about', 'About this site', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT old.id, new.name, new.title, old.content, new.author
FROM new LEFT JOIN page AS old ON new.name = old.name;
The exact form of this query can vary a bit. The key is the use of INSERT SELECT with a left outer join, to join an existing row to the new values.
Here, if a row did not previously exist, old.id will be NULL and SQLite will then assign an ID automatically, but if there already was such a row, old.id will have an actual value and this will be reused. Which is exactly what I wanted.
In fact this is very flexible. Note how the ts column is completely missing on all sides – because it has a DEFAULT value, SQLite will just do the right thing in any case, so I don’t have to take care of it myself.
You can also include a column on both the new and old sides and then use e.g. COALESCE(new.content, old.content) in the outer SELECT to say “insert the new content if there was any, otherwise keep the old content” – e.g. if you are using a fixed query and are binding the new values with placeholders.
Solution 4 - Sql
If you are generally doing updates I would ..
- Begin a transaction
- Do the update
- Check the rowcount
- If it is 0 do the insert
- Commit
If you are generally doing inserts I would
- Begin a transaction
- Try an insert
- Check for primary key violation error
- if we got an error do the update
- Commit
This way you avoid the select and you are transactionally sound on Sqlite.
Solution 5 - Sql
This answer has be updated and so the comments below no longer apply.
2018-05-18 STOP PRESS.
UPSERT support in SQLite! UPSERT syntax was added to SQLite with version 3.24.0 (pending) !
UPSERT is a special syntax addition to INSERT that causes the INSERT to behave as an UPDATE or a no-op if the INSERT would violate a uniqueness constraint. UPSERT is not standard SQL. UPSERT in SQLite follows the syntax established by PostgreSQL.
alternatively:
Another completely different way of doing this is: In my application I set my in memory rowID to be long.MaxValue when I create the row in memory. (MaxValue will never be used as an ID you will won't live long enough.... Then if rowID is not that value then it must already be in the database so needs an UPDATE if it is MaxValue then it needs an insert. This is only useful if you can track the rowIDs in your app.
Solution 6 - Sql
I realize this is an old thread but I've been working in sqlite3 as of late and came up with this method which better suited my needs of dynamically generating parameterized queries:
insert or ignore into <table>(<primaryKey>, <column1>, <column2>, ...) values(<primaryKeyValue>, <value1>, <value2>, ...);
update <table> set <column1>=<value1>, <column2>=<value2>, ... where changes()=0 and <primaryKey>=<primaryKeyValue>;
It's still 2 queries with a where clause on the update but seems to do the trick. I also have this vision in my head that sqlite can optimize away the update statement entirely if the call to changes() is greater than zero. Whether or not it actually does that is beyond my knowledge, but a man can dream can't he? ;)
For bonus points you can append this line which returns you the id of the row whether it be a newly inserted row or an existing row.
select case changes() WHEN 0 THEN last_insert_rowid() else <primaryKeyValue> end;
Solution 7 - Sql
Beginning with version 3.24.0 UPSERT is supported by SQLite.
From the documentation:
>UPSERT is a special syntax addition to INSERT that causes the INSERT to behave as an UPDATE or a no-op if the INSERT would violate a uniqueness constraint. UPSERT is not standard SQL. UPSERT in SQLite follows the syntax established by PostgreSQL. UPSERT syntax was added to SQLite with version 3.24.0 (pending). > >An UPSERT is an ordinary INSERT statement that is followed by the special ON CONFLICT clause
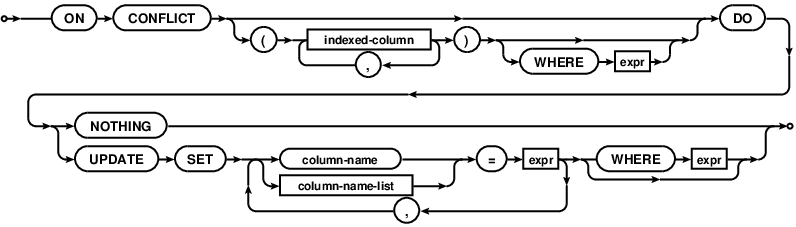
Image source: https://www.sqlite.org/images/syntax/upsert-clause.gif
Example:
CREATE TABLE t1(id INT PRIMARY KEY, c TEXT);
INSERT INTO t1(id, c) VALUES (1,'a'), (2, 'b');
SELECT * FROM t1;
INSERT INTO t1(id, c) VALUES (1, 'c');
-- UNIQUE constraint failed: t1.id
INSERT INTO t1(id, c) VALUES (1, 'c')
ON CONFLICT DO NOTHING;
SELECT * FROM t1;
INSERT INTO t1(id, c)
VALUES (1, 'c')
ON CONFLICT(id) DO UPDATE SET c = excluded.c;
SELECT * FROM t1;
Solution 8 - Sql
Here is a solution that really is an UPSERT (UPDATE or INSERT) instead of an INSERT OR REPLACE (which works differently in many situations).
It works like this:
- Try to update if a record with the same Id exists.
- If the update did not change any rows (
NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0)), then insert the record.
So either an existing record was updated or an insert will be performed.
The important detail is to use the changes() SQL function to check if the update statement hit any existing records and only perform the insert statement if it did not hit any record.
One thing to mention is that the changes() function does not return changes performed by lower-level triggers (see http://sqlite.org/lang_corefunc.html#changes), so be sure to take that into account.
Here is the SQL...
Test update:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 2;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 2, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
Test insert:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 3;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 3, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
Solution 9 - Sql
Updates from Bernhardt:
You can indeed do an upsert in SQLite, it just looks a little different than you are used to. It would look something like:
INSERT INTO table_name (id, column1, column2)
VALUES ("youruuid", "value12", "value2")
ON CONFLICT(id) DO UPDATE
SET column1 = "value1", column2 = "value2"
Solution 10 - Sql
Expanding on Aristotle’s answer you can SELECT from a dummy 'singleton' table (a table of your own creation with a single row). This avoids some duplication.
I've also kept the example portable across MySQL and SQLite and used a 'date_added' column as an example of how you could set a column only the first time.
REPLACE INTO page (
id,
name,
title,
content,
author,
date_added)
SELECT
old.id,
"about",
"About this site",
old.content,
42,
IFNULL(old.date_added,"21/05/2013")
FROM singleton
LEFT JOIN page AS old ON old.name = "about";
Solution 11 - Sql
The best approach I know is to do an update, followed by an insert. The "overhead of a select" is necessary, but it is not a terrible burden since you are searching on the primary key, which is fast.
You should be able to modify the below statements with your table & field names to do what you want.
--first, update any matches
UPDATE DESTINATION_TABLE DT
SET
MY_FIELD1 = (
SELECT MY_FIELD1
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
,MY_FIELD2 = (
SELECT MY_FIELD2
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
WHERE EXISTS(
SELECT ST2.PRIMARY_KEY
FROM
SOURCE_TABLE ST2
,DESTINATION_TABLE DT2
WHERE ST2.PRIMARY_KEY = DT2.PRIMARY_KEY
);
--second, insert any non-matches
INSERT INTO DESTINATION_TABLE(
MY_FIELD1
,MY_FIELD2
)
SELECT
ST.MY_FIELD1
,NULL AS MY_FIELD2 --insert NULL into this field
FROM
SOURCE_TABLE ST
WHERE NOT EXISTS(
SELECT DT2.PRIMARY_KEY
FROM DESTINATION_TABLE DT2
WHERE DT2.PRIMARY_KEY = ST.PRIMARY_KEY
);
Solution 12 - Sql
If someone wants to read my solution for SQLite in Cordova, I got this generic js method thanks to @david answer above.
function addOrUpdateRecords(tableName, values, callback) {
get_columnNames(tableName, function (data) {
var columnNames = data;
myDb.transaction(function (transaction) {
var query_update = "";
var query_insert = "";
var update_string = "UPDATE " + tableName + " SET ";
var insert_string = "INSERT INTO " + tableName + " SELECT ";
myDb.transaction(function (transaction) {
// Data from the array [[data1, ... datan],[()],[()]...]:
$.each(values, function (index1, value1) {
var sel_str = "";
var upd_str = "";
var remoteid = "";
$.each(value1, function (index2, value2) {
if (index2 == 0) remoteid = value2;
upd_str = upd_str + columnNames[index2] + "='" + value2 + "', ";
sel_str = sel_str + "'" + value2 + "', ";
});
sel_str = sel_str.substr(0, sel_str.length - 2);
sel_str = sel_str + " WHERE NOT EXISTS(SELECT changes() AS change FROM "+tableName+" WHERE change <> 0);";
upd_str = upd_str.substr(0, upd_str.length - 2);
upd_str = upd_str + " WHERE remoteid = '" + remoteid + "';";
query_update = update_string + upd_str;
query_insert = insert_string + sel_str;
// Start transaction:
transaction.executeSql(query_update);
transaction.executeSql(query_insert);
});
}, function (error) {
callback("Error: " + error);
}, function () {
callback("Success");
});
});
});
}
So, first pick up the column names with this function:
function get_columnNames(tableName, callback) {
myDb.transaction(function (transaction) {
var query_exec = "SELECT name, sql FROM sqlite_master WHERE type='table' AND name ='" + tableName + "'";
transaction.executeSql(query_exec, [], function (tx, results) {
var columnParts = results.rows.item(0).sql.replace(/^[^\(]+\(([^\)]+)\)/g, '$1').split(','); ///// RegEx
var columnNames = [];
for (i in columnParts) {
if (typeof columnParts[i] === 'string')
columnNames.push(columnParts[i].split(" ")[0]);
};
callback(columnNames);
});
});
}
Then build the transactions programmatically.
"Values" is an array you should build before and it represents the rows you want to insert or update into the table.
"remoteid" is the id I used as a reference, since I'm syncing with my remote server.
For the use of the SQLite Cordova plugin, please refer to the official link
Solution 13 - Sql
I think this may be what you are looking for: ON CONFLICT clause.
If you define your table like this:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
field1 TEXT
);
Now, if you do an INSERT with an id that already exists, SQLite automagically does UPDATE instead of INSERT.
Hth...
Solution 14 - Sql
This method remixes a few of the other methods from answer in for this question and incorporates the use of CTE (Common Table Expressions). I will introduce the query then explain why I did what I did.
I would like to change the last name for employee 300 to DAVIS if there is an employee 300. Otherwise, I will add a new employee.
Table Name: employees Columns: id, first_name, last_name
The query is:
INSERT OR REPLACE INTO employees (employee_id, first_name, last_name)
WITH registered_employees AS ( --CTE for checking if the row exists or not
SELECT --this is needed to ensure that the null row comes second
*
FROM (
SELECT --an existing row
*
FROM
employees
WHERE
employee_id = '300'
UNION
SELECT --a dummy row if the original cannot be found
NULL AS employee_id,
NULL AS first_name,
NULL AS last_name
)
ORDER BY
employee_id IS NULL --we want nulls to be last
LIMIT 1 --we only want one row from this statement
)
SELECT --this is where you provide defaults for what you would like to insert
registered_employees.employee_id, --if this is null the SQLite default will be used
COALESCE(registered_employees.first_name, 'SALLY'),
'DAVIS'
FROM
registered_employees
;
Basically, I used the CTE to reduce the number of times the select statement has to be used to determine default values. Since this is a CTE, we just select the columns we want from the table and the INSERT statement uses this.
Now you can decide what defaults you want to use by replacing the nulls, in the COALESCE function with what the values should be.
Solution 15 - Sql
Following Aristotle Pagaltzis and the idea of COALESCE from Eric B’s answer, here it is an upsert option to update only few columns or insert full row if it does not exist.
In this case, imagine that title and content should be updated, keeping the other old values when existing and inserting supplied ones when name not found:
NOTE id is forced to be NULL when INSERT as it is supposed to be autoincrement. If it is just a generated primary key then COALESCE can also be used (see Aristotle Pagaltzis comment).
WITH new (id, name, title, content, author)
AS ( VALUES(100, 'about', 'About this site', 'Whatever new content here', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT
old.id, COALESCE(old.name, new.name),
new.title, new.content,
COALESCE(old.author, new.author)
FROM new LEFT JOIN page AS old ON new.name = old.name;
So the general rule would be, if you want to keep old values, use COALESCE, when you want to update values, use new.fieldname
Solution 16 - Sql
If you don't mind doing this in two operations.
Steps:
-
Add new items with "INSERT OR IGNORE"
-
Update existing items with "UPDATE"
The input to both steps is the same collection of new or update-able items. Works fine with existing items that need no changes. They will be updated, but with the same data and therefore net result is no changes.
Sure, slower, etc. Inefficient. Yep.
Easy to write the sql and maintain and understand it? Definitely.
It's a trade-off to consider. Works great for small upserts. Works great for those that don't mind sacrificing efficiency for code maintainability.
Solution 17 - Sql
Complete example of upserting using WHERE to select the newer dated record.
-- https://www.db-fiddle.com/f/7jyj4n76MZHLLk2yszB6XD/22
DROP TABLE IF EXISTS db;
CREATE TABLE db
(
id PRIMARY KEY,
updated_at,
other
);
-- initial INSERT
INSERT INTO db (id,updated_at,other) VALUES(1,1,1);
SELECT * FROM db;
-- INSERT without WHERE
INSERT INTO db (id,updated_at,other) VALUES(1,2,2)
ON CONFLICT(id) DO UPDATE SET updated_at=excluded.updated_at;
SELECT * FROM db;
-- WHERE is FALSE
INSERT INTO db (id,updated_at,other) VALUES(1,2,3)
ON CONFLICT(id) DO UPDATE SET updated_at=excluded.updated_at, other=excluded.other
WHERE excluded.updated_at > updated_at;
SELECT * FROM db;
-- ok to SET a PRIMARY KEY. WHERE is TRUE
INSERT INTO db (id,updated_at,other) VALUES(1,3,4)
ON CONFLICT(id) DO UPDATE SET id=excluded.id, updated_at=excluded.updated_at, other=excluded.other
WHERE excluded.updated_at > updated_at;
SELECT * FROM db;
Solution 18 - Sql
Having just read this thread and been disappointed that it wasn't easy to just to this "UPSERT"ing, I investigated further...
You can actually do this directly and easily in SQLITE.
Instead of using: INSERT INTO
Use: INSERT OR REPLACE INTO
This does exactly what you want it to do!
Solution 19 - Sql
SELECT COUNT(*) FROM table1 WHERE id = 1;
if COUNT(*) = 0
INSERT INTO table1(col1, col2, cole) VALUES(var1,var2,var3);
else if COUNT(*) > 0
UPDATE table1 SET col1 = var4, col2 = var5, col3 = var6 WHERE id = 1;